基础知识之三——标准单元库
综述
Synopsys_工艺库格式是事实上的库标准。对库格式和延时计算方法的基本理解是成功综合的关键Synopsys工艺库可分为两大类:
逻辑库:包含仅与综合过程有关的信息且通过DC用于设计的综合和优化。如pin到pin的时序、面积、引脚类型等
物理库:包含单元的物理特征,如物理尺寸、层信息、单元方位等。
半导体厂商提供给我们DC兼容的工艺技术库——综合库来进行逻辑综合。大多数情况下,半导体厂商提供二进制格式的.db文件,也有可能只提供文本(ASCII)格式的.lib文件,或两者。DC使用的综合库必须是.db格式的库。因此,如果我们只有.lib文件,需要用Library Compiler将其转换为.db文件。
综合库的结构如下图所示。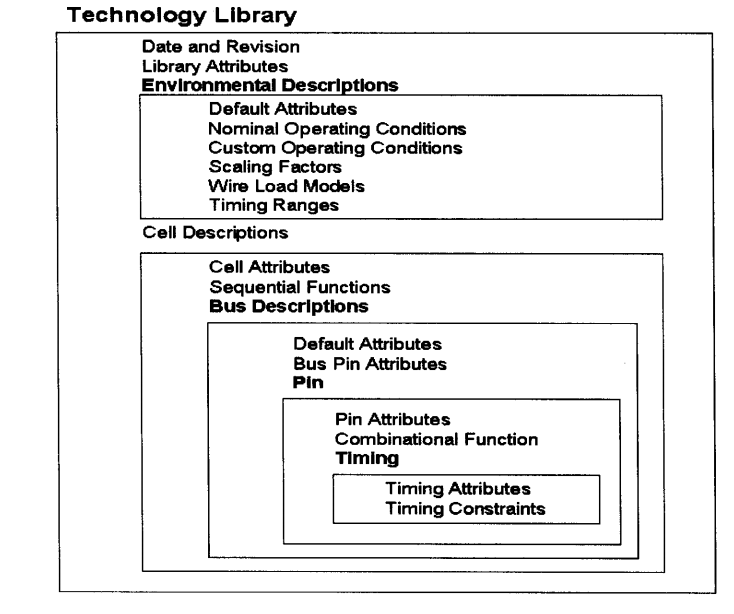 ?
?
可以将其分为两个部分,标题部分与单元描述部分。我们使用smic180工艺下的typical.lib进行分析。
其中标题部分主要是介绍使用的延时模型,工艺角,库的名称等一些公共部分,后面的部分是库里单元的描述,也是这个文件的主要部分。文档一共214835行,其中第一部分一共由250行左右进行描述,剩下的都是对单元的描述。
对应的文本描述如下所示。下面也将通过介绍标题部分以及特定的几个单元描述来进行总结学习。参考的smic180-typical.lib。可能不同的库的内容有所不同,但都是大同小异的。

库属性部分
- 库组(library group)
- 工艺库的一般属性(general attributes)
- 库文档资料(documentation attributes)
- 单位定义(unit attributes)
1,库组(library Group)
库组指令定义工艺库名。这个指令必须是在库文件中的第一个可执行行。例如:
library(my_library)
{
…}
2,工艺库的一般属性(general attributes)
包括以下属性
/* general attributes */ |
1)technology 工艺类型
工艺属性定义用来区别时序分析的设计是基于那种类型的设计。目前有两种类型的设计需要时序分析,一种是ASIC设计,一种是FPGA设计。但是它们在设计流程上有很大的不同,所以在进行时序分析时也有所区别。因此工艺属性有两个设置值可以选择:CMOS和FPGA。
工艺属性识别库中使用的工艺类型:CMOS(预设值)、 FPGA。工艺类型必须先定义,放在属性清单的顶部。如果库中没有技术属性,Library Compiler预设其为cmos。
2)in_place_swap_mode
设计工具需要对设计进行时序和功耗优化,最基本的方法就是把不合适的单元替换成合适的单元。但是是否可以允许设计工具进行单元替换优化操作,需要在时序信息文件中通过单元优化替换属性进行定义。因此单元优化替换属性有两个设置值可以选择:match footprint和no swapping。
3)library_features
工艺库特征属性定义其他Synopsys工具可以使用具有该工艺库特征定义的命令进行设计。工艺库特征属性有5个设置值可以选择:report_delay_calculation、report_power_calculation、report_noise_calculation、report_user_data和allow_update_attribute。
4)delay_model 延时模型
指明在计算延迟时用的那个模型,主要有generic_cmos(默认值)、table-lookup(非线性模型)、piecewise-cmos(optional)、dcm(Delay Calculation Module)、polynomial。如果库组中没有定义延时模型属性,那么默认设置是generic_cmos。
a)非线性模型
大多数单元库都包括表格模型(table model),用于为单元的各种时序弧指定延迟并进行时序检查。 这些表格模型被称为NLDM(Non-Linear Delay Model),可用于延迟、输出压摆计算或其他时序检查。表格模型中提供了:在单元输入引脚处输入过渡时间和输出引脚处输出负载电容的各种组合下通过单元的延迟。
CMOS非线性延时计算模型(NLDM)是一种时序计算精度较高的延时计算模型。在Synopsys工艺库模型中,目前业界主要使用非线性延时计算模型。该延时模型由==输入信号转换时间==与==输出负载==作为索引,时序分析时以一个二维查找表的形式来计算延时,查找表中时序数据的实际构成如下图所示。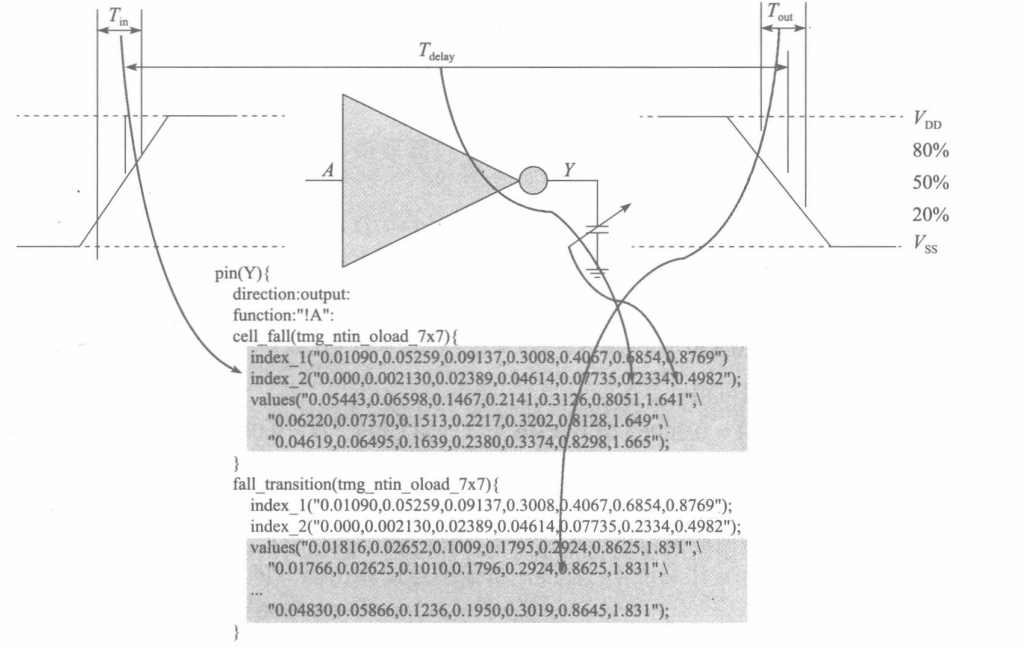
基于非线性延时计算模型通常的计算过程为:查找表中索引参数的某个采样点延时可直接查表得出,再通过插值算法来计算延时。通过非线性延时计算模型计算所能达到的精度有赖于采样点选取的合理性以及所用的插值算法。只要采样点较为合理,采用一般的多项式插值算法就能取得较好的延时结果。延时的一般插值计算方法如图所示
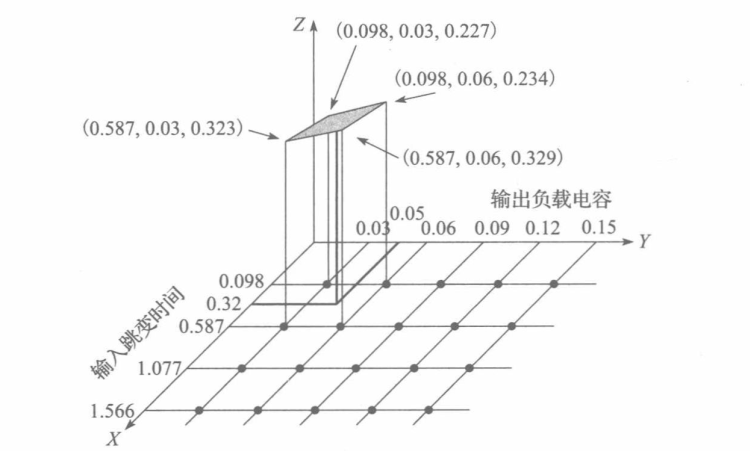
三维坐标中,X为输入端口信号的跳变时间Transition time(ns),y为输出端负载电容值Cload(pf),Z为延时值Tdelay(ns),计算式为Z=A+B·X+C·Y+D·X·Y如果要计算X=0.32、Y=0.05时的Z值,只需取最接近X、Y的4个采样点。构建如下方程
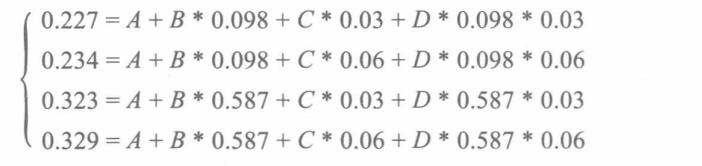
A=0.2006,B=0.1983,C=0.2399,D=0.0677。带入X、Y即可

现已经通过查找表与插值的方式计算得到了单元延时。
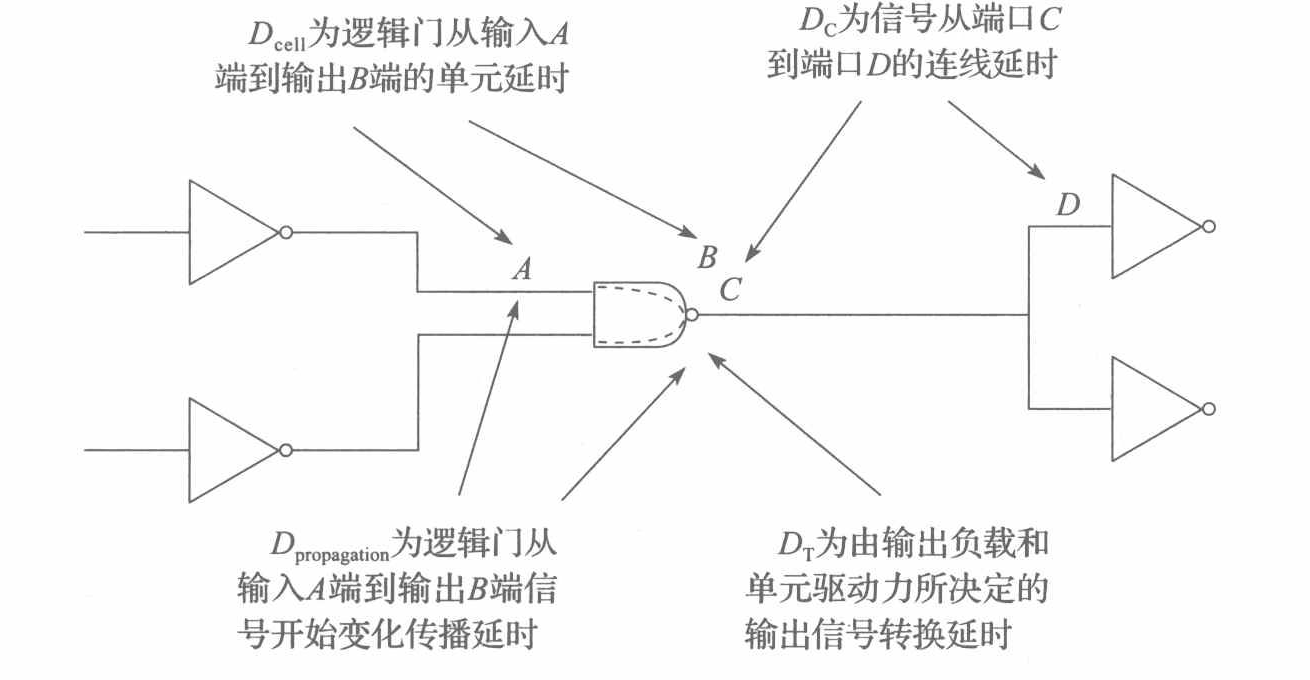
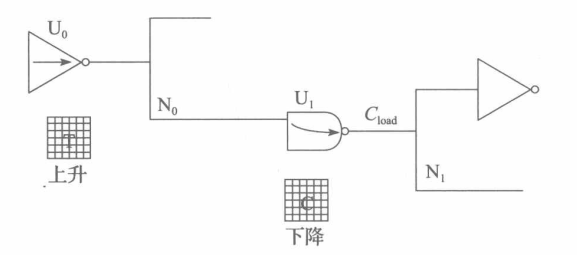
Dc是通过WLM(wire load model)以及type_tree来进行计算的,参看文章后续的这两个部分即可得到线延时。

如下图所示,计算逻辑门U1的Dcell值时,先确定输入端口的转换时间,U1输入端口的转换时间由前级单元U0的输出决定。当U0的输出为上升(rise)转换时间时,由于U1的时序弧为反向时序弧,因此U1的逻辑门延时应该在对应的U1下降时序弧查找表中进行插值计算。由于下降时序弧查找表是二维表,因此还需要确定U1输出端负载值,通过互连线负载模型和驱动节点负载值得到输出端总负载值。最后,根据U1输入端口转换时间和输出端负载电容值作为索引,在对应的U1下降时序弧二维查找表得到相应数据,并进行插值计算直接得到延时。
3,库文档资料(documentation attributes)
主要是库的版本、库的日期、还有注释。
revision : ***; |
4,单位定义(unit attributes)
Design Compiler工具本身是没有单位的。然而在建立工艺库和产生报告时,必须要有单位。库中有6个库级属性定义单位:
time_unit : "1ns"; 时间单位 |
单元描述中数值的单位都是在库中指定的,可使用Liberty命令集在库文件中声明单位。
环境属性部分
- 操作环境(operation conditions)
- 阈值定义(threshold definitions)
- 默认环境属性(default attributes)
- 模板(templates)
- 比例缩放因子(k-factors)
- I/Opad属性(pad attributes)
- 线负载模型(wire-loads)
1,工作条件(operation conditions)
指定了工艺、温度、电压以及RC树模型,用于设计的综合和时序分析。

这里就是对于库基本的情况进行了说明。会与slow.lib内容不同。主要是对于温度、电压等操作环境进行说明。

这里的工作条件与我们之前了解的PVT环境联系到了一起。
1)tree_type
tree type属性定义了使用的环境互连模型,DC在计算互连延迟时使用这一属性值来选择合适的公式。
对于预布局估计,可以使用以下三种不同形式来表示互连RC树。请注意,每个互连线的总长度(以及电阻和电容估计值)在这三种情况下是相同的。
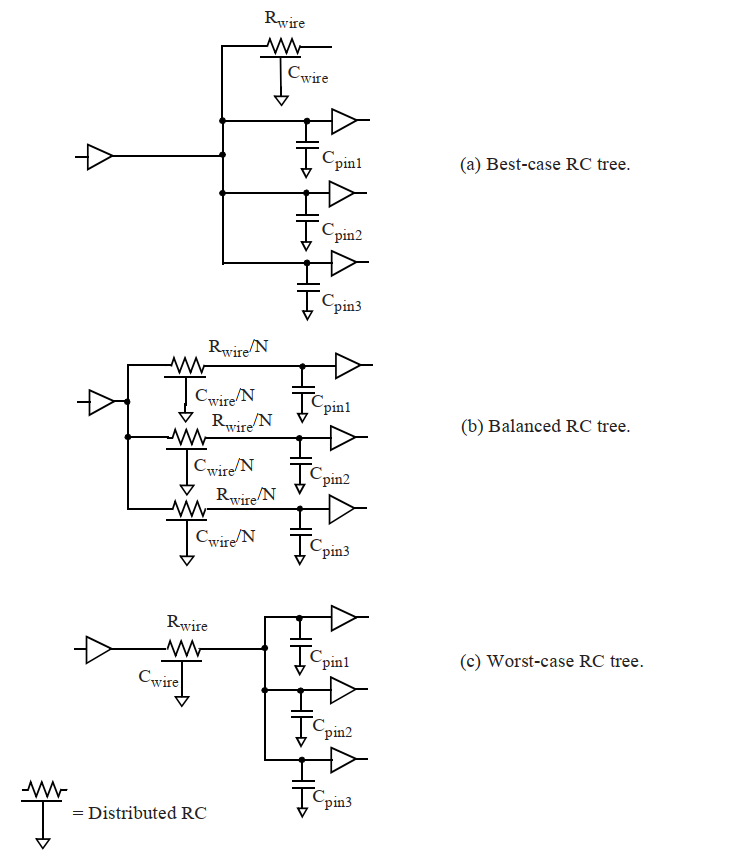
Best-case tree:在最佳情况树中,假定负载引脚在物理上与驱动引脚相邻。因此,到负载引脚的路径中都没有互连电阻,来自其它扇出引脚的所有互连线电容和引脚电容仍然作为驱动引脚上的负载。
Balanced tree:在这种情况下,假定每个负载引脚都在互连线的一部分上,并且每条到达负载引脚的路径上的总电阻和电容都相等。
Worst-case tree :在最差情况树中,假定所有负载引脚都集中在互连线的另一端。因此,每条到负载引脚的路径上都会有全部的互连线电阻和电容。
2,阈值定义(threshold definitions)
压摆值(slew)基于的是在库中指定的测量阈值点,大多数上一代的库(0.25um或更旧的库)都使用10%和90%作为压摆(或称过渡时间)的测量阈值点。
压摆阈值点的选择对应的是波形的线性部分。随着技术的发展,实际波形最线性的部分通常在30%至70%之间。 因此,大多数新一代时序库都将压摆测量阈值点指定为Vdd的30%和70%。但是,由于之前测得的过渡时间在10%至90%之间,因此在填充库时,通常将测得的30%至70%的过渡时间加倍,这由压摆降额系数(slew derate factor)指定,通常指定为0.5。压摆测量阈值点为30%和70%且压摆降额系数为0.5,等效于测量阈值点为10%和90%。 阈值设置的示例如下:
slew_lower_threshold_pct_fall : 30.0; |
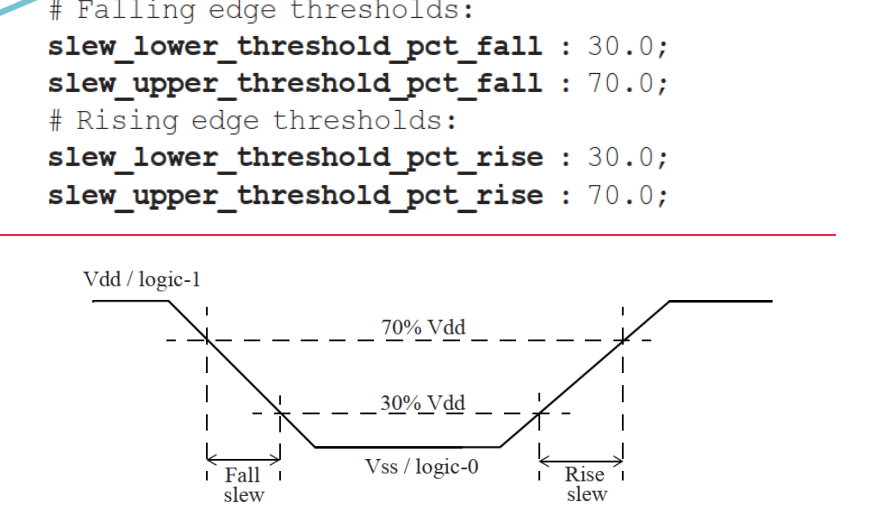
上面的设置规定了要将表格中的过渡时间乘以0.5,以获得与阈值(30%-70%)设置相对应的过渡时间。这意味着表格中的值(以及相应的索引值)实际上是10%-90%阈值点的测量值。在标定过渡时间值时,首先在30%-70%处测量,然后再把测量值外推到10%至90%((70-30)/(90-10)= 0.5)。
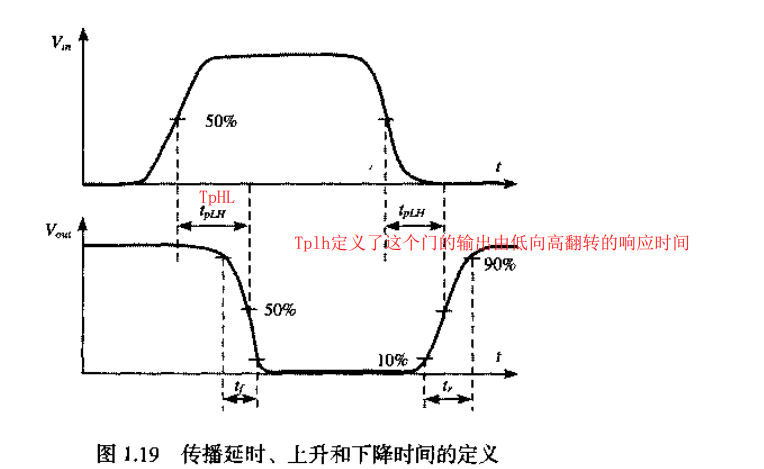
未指定slew_derate_from_library(默认值为1.0),这意味着库中的过渡时间不会降额(derate)
3,默认环境属性(default attributes)
/* default attributes */ |
1)漏电功率(leakage_power)
大多数标准单元的设计都仅在输出或状态发生变化时才消耗功率。单元通了电但没有任何行为时,所有功耗都归因于泄漏电流(leakage current)。泄漏可能是由于MOS器件的亚阈值电流引起的,也可能是由于通过栅极氧化物的隧穿电流引起的。在以前的CMOS工艺技术中,漏电功率可以忽略不计,并且在设计过程中并不是主要考虑因素。但是,随着技术的发展,漏电功率变得越来越大,与有功功率相比,漏电功率已经无法忽略不计了。
如上所述,漏电功率主要有两个来源:MOS器件中的亚阈值电流和栅氧化物隧穿。通过使用高阈值电压单元,可以降低亚阈值电流;然而,由于高阈值电压单元的速度较低而存在一个折中(rde-of):高阈值电压单元的漏电较小,但速度较慢。同样,低阈值电压单元的漏电较大,但速度较高。无论是使用高阈值电压还是低阈值电压的单元,栅极氧化物隧穿带来的影响都差不多。因此,控制漏电功率的可能方法是使用高阈值电压的单元。类似于在高阈值电压和标准阈值电压单元之间进行选择,设计中使用的单元强度(strength)也是一种漏电和速度之间的折中。强度较高的单元具有较高的漏电功率,但速度较高。
MOS器件的亚阈值泄漏电流与温度具有很强的非线性特性,在大多数工艺技术中,随着器件温度从25°C升高到125°C,亚阈值泄漏电流可能会增加10倍至20倍。栅极氧化物隧穿带来的影响基本不随温度或器件阈值电压而改变,在100m及以上工艺技术中可以忽略的栅极氧化物隧穿已成为65nm或更精细技术在较低温度下漏电的主要原因。例如,对于65m或更精细的工艺技术,栅极氧化物隧穿漏电量可能等于室温下的亚阈值漏电量。而在高温下,亚阈值漏电仍然是导致漏电功率的主要因素。
4,模板(templates)
这里提供了很多查找表的模板。
1)功耗查找表模板组(power lut template group)
功耗查找表模板组(power lut template group)是库组中为其他功耗相关组所调用的查找表模板,通过该模板可以构成一维到三维的查找表结构,如下所示。

如上所示存在3个不同的变量:variable1、variable2和variable3,对应的变量参数值也存在3种:total_output_net_capacitance、equal_or_opposite_output_net_capacitance和input_transition_time。通过3个索引变量index1、index2和index3的值来确定最终的功耗结果。
举例如下:
power_lut_template(energy_template_7x3x3) { |
b)延时查找表模板组(lu_table_template_group)
延时查找表模板组(lu_table_template_group)是库组中为其他延时相关组所调用的查找表模板,通过该模板可以构成一维到三维的查找表结构,如下所示。

与功耗查找表模板组结构类似,延时查找表模板组存在3个不同的变量:variable1、variable2和variable3,其中变量参数值根据所调用的延时相关组的不同而不同,主要包括以下变量参数值:input_voltage、output_voltagefanout_number、fanout_pin_capacitance、driver_slew、input_net_transition和total_output_net_capacitance等,通过3个索引变量index 1、index2和index3的值来确定最终的延时结果。
举例如下:
power_lut_template(energy_template_7x7) { |
这里还有很多其他的模板,不一一列举
5,比例缩放因子(k-factors)
库的表征是一个耗时的过程,针对各种工艺角(process corner)对库进行表征可能需要数周的时间,工艺变量的设置使得以特定工艺角为特征的库可以用于不同工艺角的时序计算。工艺的k-系数可用于完成从特征库工艺到目标工艺的延迟降额。如上所述,降额系数的使用在时序计算期间引入了不准确性,跨工艺条件进行降额尤其不准确,因此很少采用。总而言之,指定不同工艺变量值(例如1.0或任何其它值)的唯一功能就是在少数情况下允许跨工艺条件进行降额处理。
与作为物理量的温度和电压不同,工艺是不可量化的变量。就数字特征和验证而言,它可能是缓慢(slow)、典型(typical)或快速(fast)的工艺之一。 工作条件(nom_process、nom_temperature和nom_voltage)指定了对库进行表征的工艺、电压和温度, 也指定了使用该库中单元的条件。如果特征和工作条件不同,则需要对延迟计算过程中获得的时序值进行降额(derate)处理, 这可以通过使用库中指定的降额系数(k-系数)来实现 。使得时序分析的结果更接近真实值。
当延迟计算过程中工作条件的工艺、电压或温度与库中的标称条件不同时,可使用这些系数来进行计算。注意,k_volt系数为负,这意味着延迟随着电压的增加而减小,而k_temp因子为正,这意味着延迟通常随温度的升高而增加 。


形式如下所示:
/* k-factors */ |
6,I/Opad属性(pad attributes)
定义I/O引脚的电平属性,告诉你输入是COMS还是TTL,什么时候达到高电平、什么时候是低电平。
/* pad attributes */ |
7,线负载模型(wire-loads)
在进行布局规划(floorplanning)或布局(layout)之前,可以使用线负载模型(wireload models)来估计由互连线带来的电容、电阻以及面积开销。 线负载模型可用于根据扇出数量来估计网络的长度,线负载模型取决于块(block)的面积,具有不同面积的设计可以选择不同的线负载模型。线负载模型还可以将网络的估计长度映射(map)为电阻、电容以及由于布线而产生的相应面积开销。 形式如下:
/* wire-loads */ |
其中参数wire load定义线负载模型的名称,参数resistance定义互连线单位电阻值,参数capacitance定义互连线单位电容值,参数area定义互连线单位长度的面积值,参数slope定义扩展斜率值,参数fanout length定义对应扇出大小的互连线长度。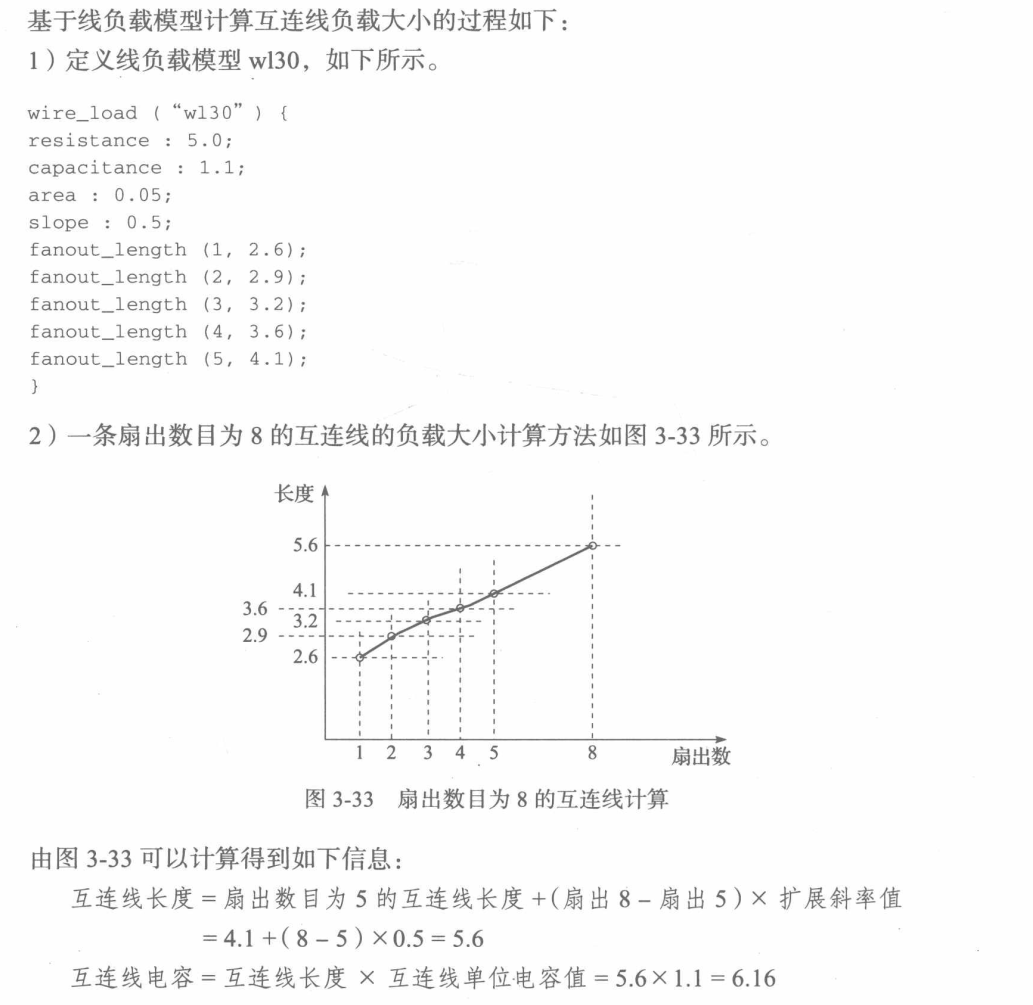

至此,我们得到了互连线的电阻与电容。
补充:tree-type与线负载模型的关系
线负载模型(WLM)是根据连线的扇出来估算连线的RC寄生参数那么RC是如何分配呢?
操作条件中有“tree-type’”的属性,该属性决定R和C的分配以计算时间延迟这也是tree-type与线负载模型的关系,也是笔者学习的时候不是很好理解的部分。
简单来说就是需要用线负载模型去计算一个R,C,那么RC是怎么影响延时的呢,就是看其在电路中的拓扑结构。

这里的图与上述tree_type部分介绍的实际上是一致的。
单元描述部分
- 单元描述
该部分提供了库里标准单元的描述。标准单元也可以在提供的doc下的文档中找到。文档标题如下

这里使用几个特殊的标准单元进行学习。DFFR,以及INV。其余基本上是一致的。
1,INV

lib中的描述如下:
cell (INVX20) { |
1)引脚电容
单元的每个输入和输出都可以在引脚(pin)上指定电容。在大多数情况下,仅为单元输入引脚指定电容,而不为输出引脚指定
电容,即大多数单元库中的输出引脚电容为0。
2)internal power
内部开关功率在单元库中被称为internal power,这是当单元的输入或输出处于活动状态时单元内部的功耗。对于组合逻辑单元,输入引脚的电平跳变会导致输出引脚的电平跳变,从而导致内部开关功耗。
3)时序模型
逻辑单元的时序模型(timing model)旨在为设计中的各种单元实例(instance)提供准确的时序信息。通常会从单元的详细电路仿真中获得时序模型,用以对单元工作时的实际情况进行建模,且需要为逻辑单元的每个时序弧都建立一个时序模型。
表征反相器的两种延迟是:
Tr:输出上升沿延迟
Tf:输出下降沿延迟
通过反相器的时序弧的延迟取决于两个因素 input_net_transition以及total_output_net_capacitance。
逻辑单元输出引脚的压摆(slew)主要取决于输出引脚电容:输出信号过渡时间会随着输出负载的增加而增加。 因此,在输入端压摆较大(输入信号过渡时间较长)的情况下,选择合适的单元类型及输出负载,可以改善输出端的压摆。 下图展示了通过调节逻辑单元的输出负载,可以改善或恶化单元输出信号过渡时间的情况。
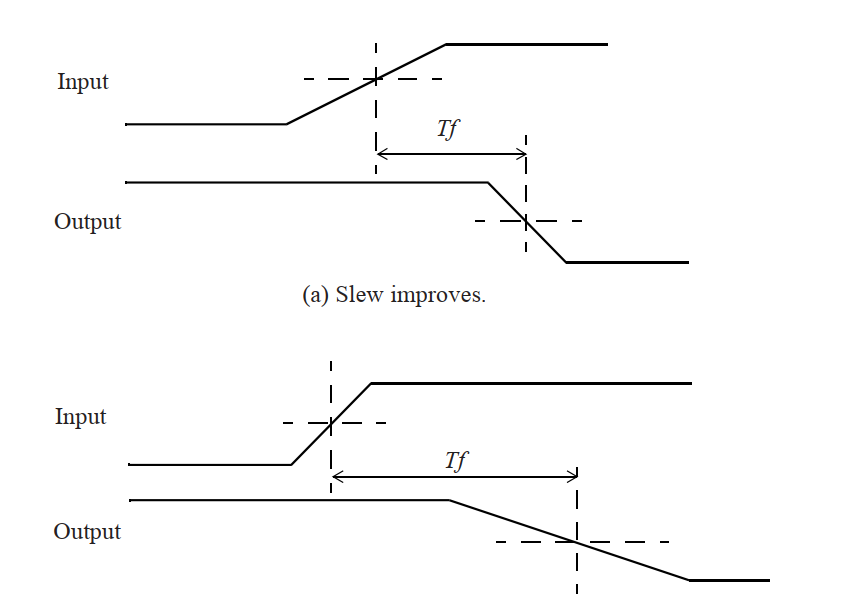
一个简单的时序模型是 linear delay 模型,其中单元的延迟和输出转换时间表示为两个参数的线性函数:输入转换时间和输出负载电容。通过单元的延迟 D 的线性模型的一般形式如下所示:D=D0+D1*S+D2*C其中D0,D1,D2是常数,S是输入过渡时间,C是输出负载电容
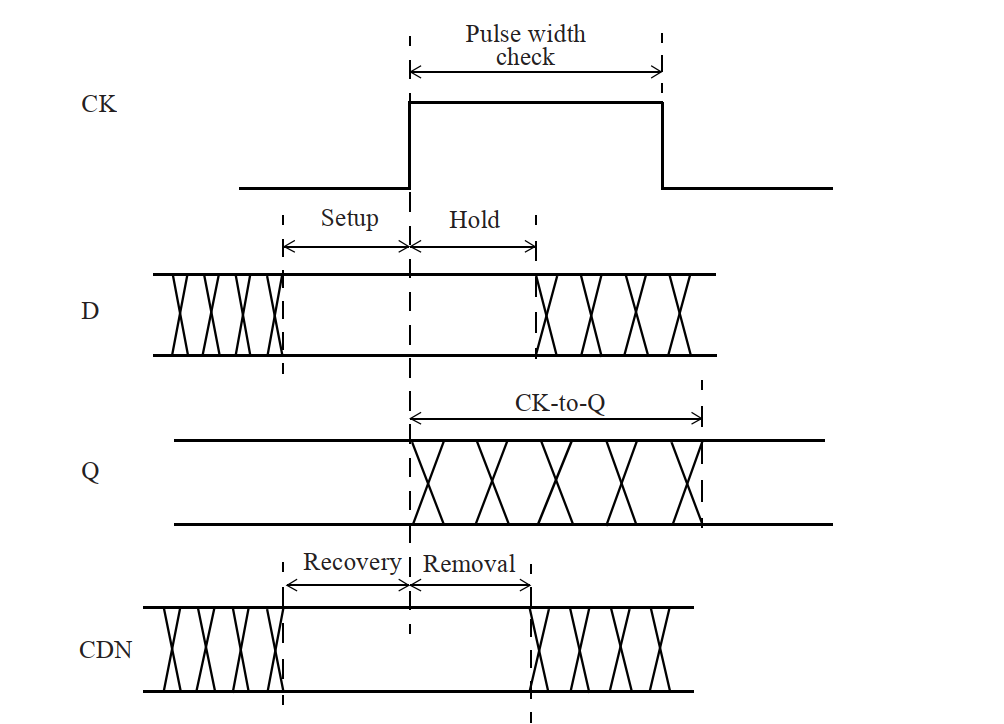
2,DFFR
先看文档描述如下图,可以看到有四种不同驱动强度的,对应这不同的size。我们选择DFFRX4的工艺库文件进行学习。这是一个带复位的寄存器。
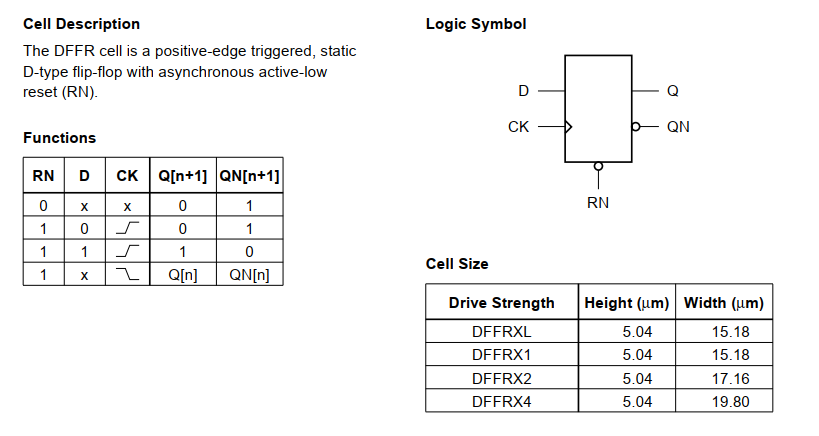
我们对DFFRX4的lib内容进行学习,开始同样是cellname,area以及功耗。我们略过看时序的部分。
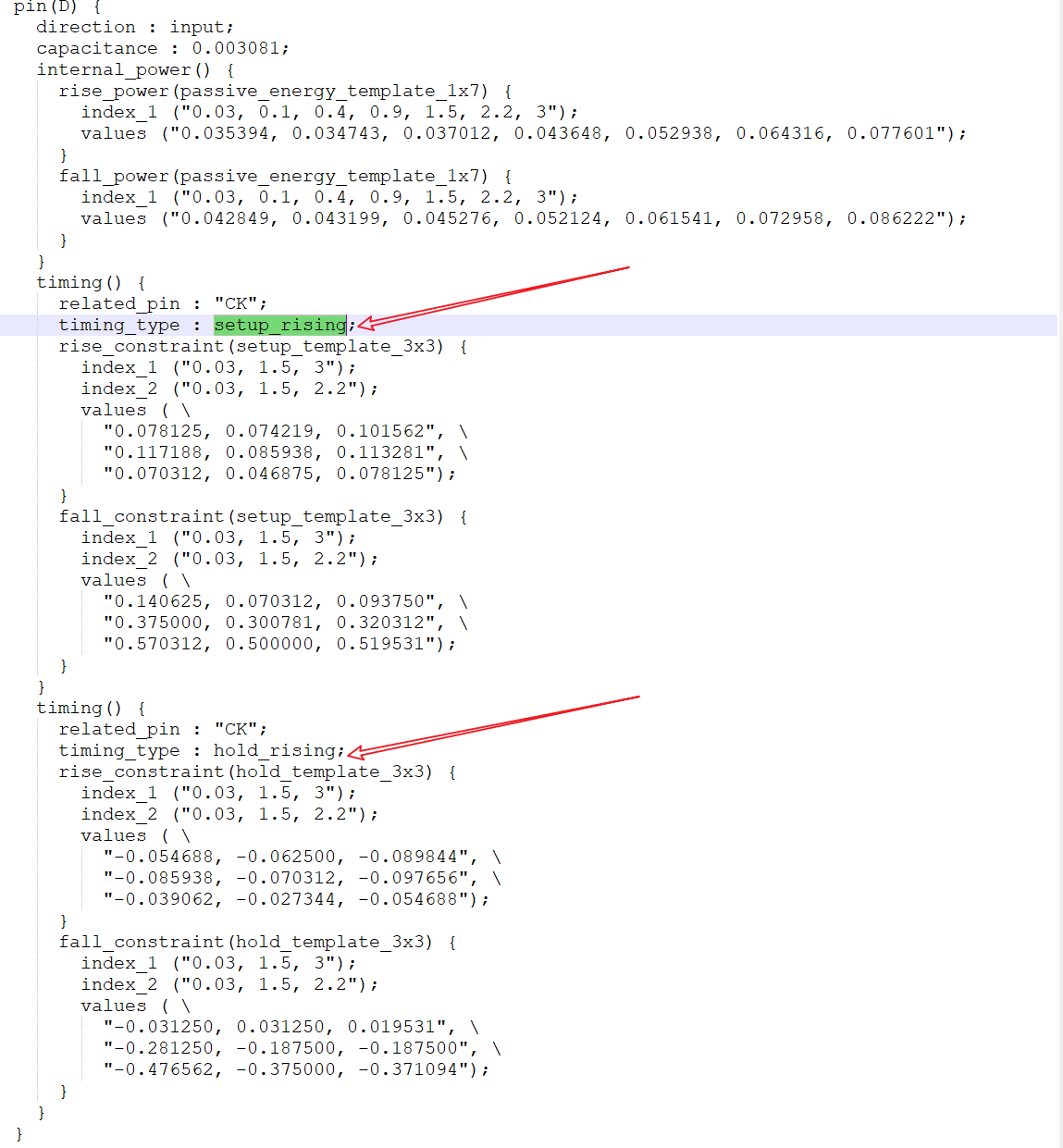
setup_rising指相关引脚D的上升和下降建立时间。hold_rising是对应的保持时间。这就是我们STA里说到的。这里会进行计算。
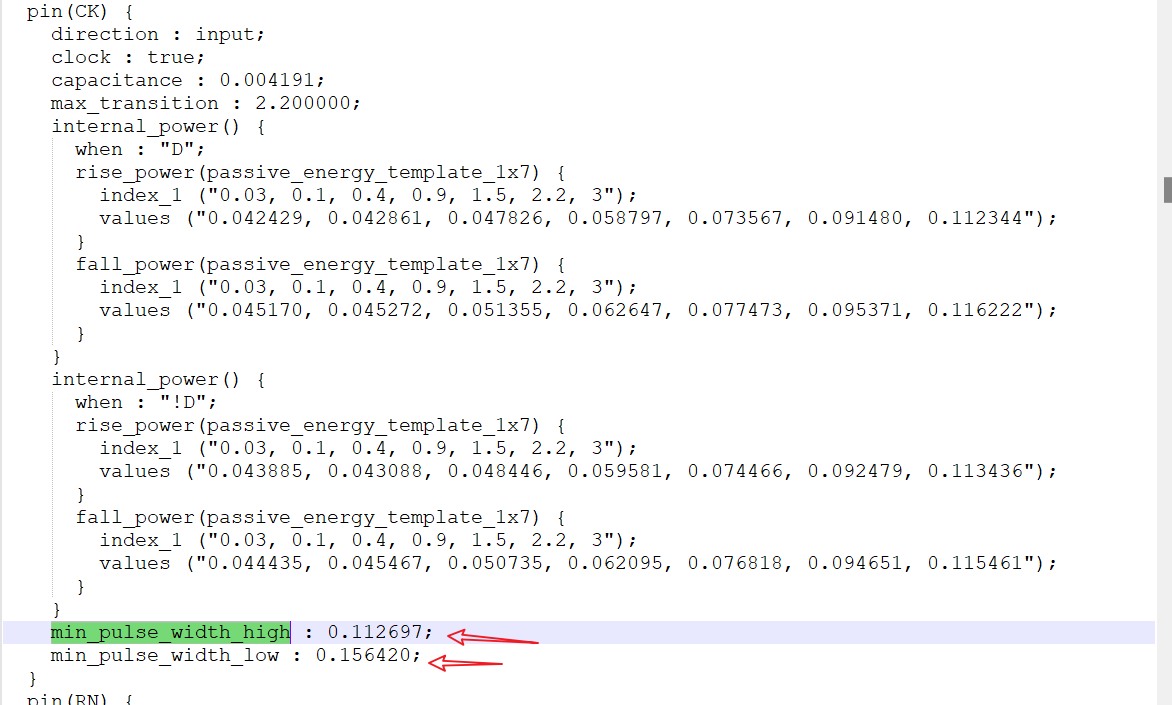
脉冲宽度检查 。对于CK引脚有了脉冲宽度的检查,也是对时钟另一种约束,类似于出现毛刺,或者是超高频,DFF就不可以正常工作,这里随着工艺会不断改变。
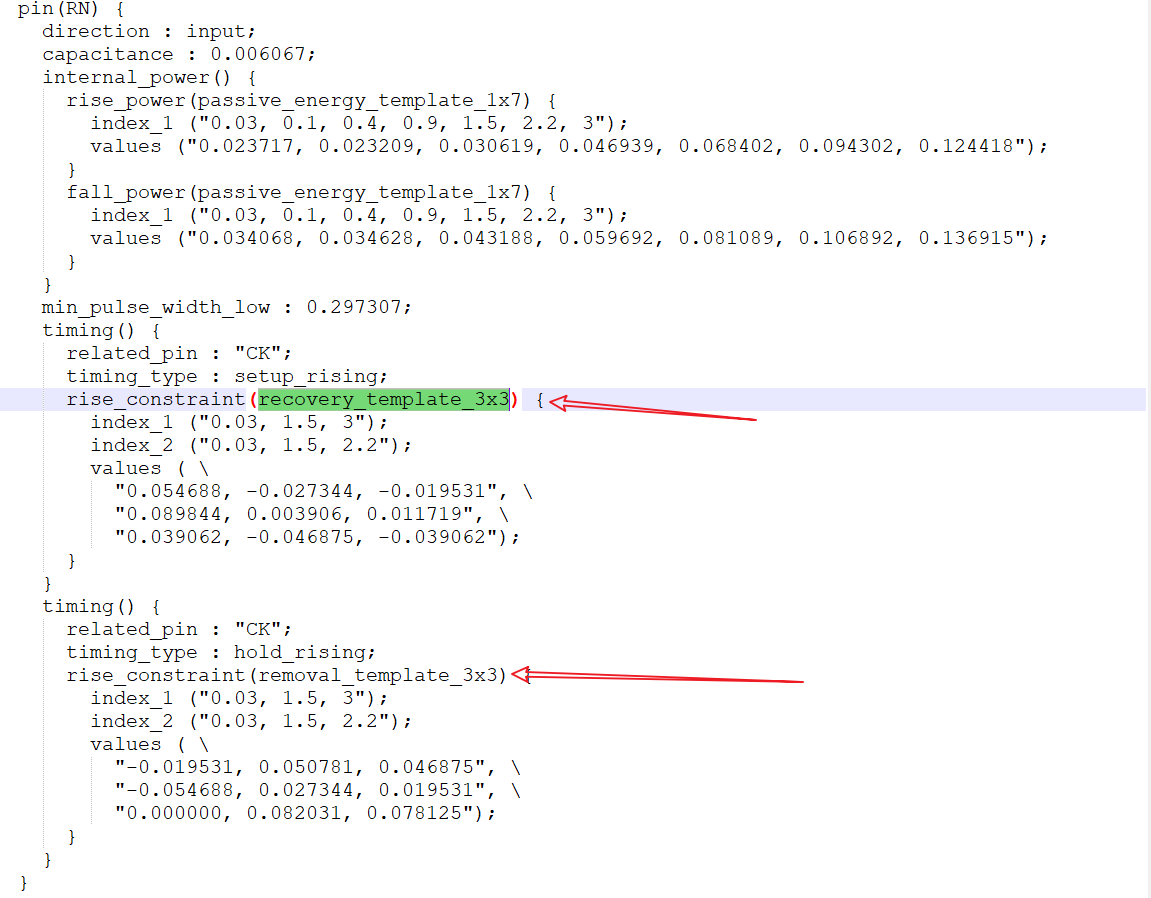
对于复位引脚recover与removal的时序要求如上图所示。接下来就是输出了。

首先是对功能的描述,其次就是对PIN(Q)功耗的查找表。我们重点关注时序信息。
非单边类型(non-unate)的时序弧 。(在非单边(non-unate)时序弧中,仅仅从一个输入引脚的跳变方向是无法确定输出引脚电平将如何跳变的,还要取决于其他输入引脚的状态。 )
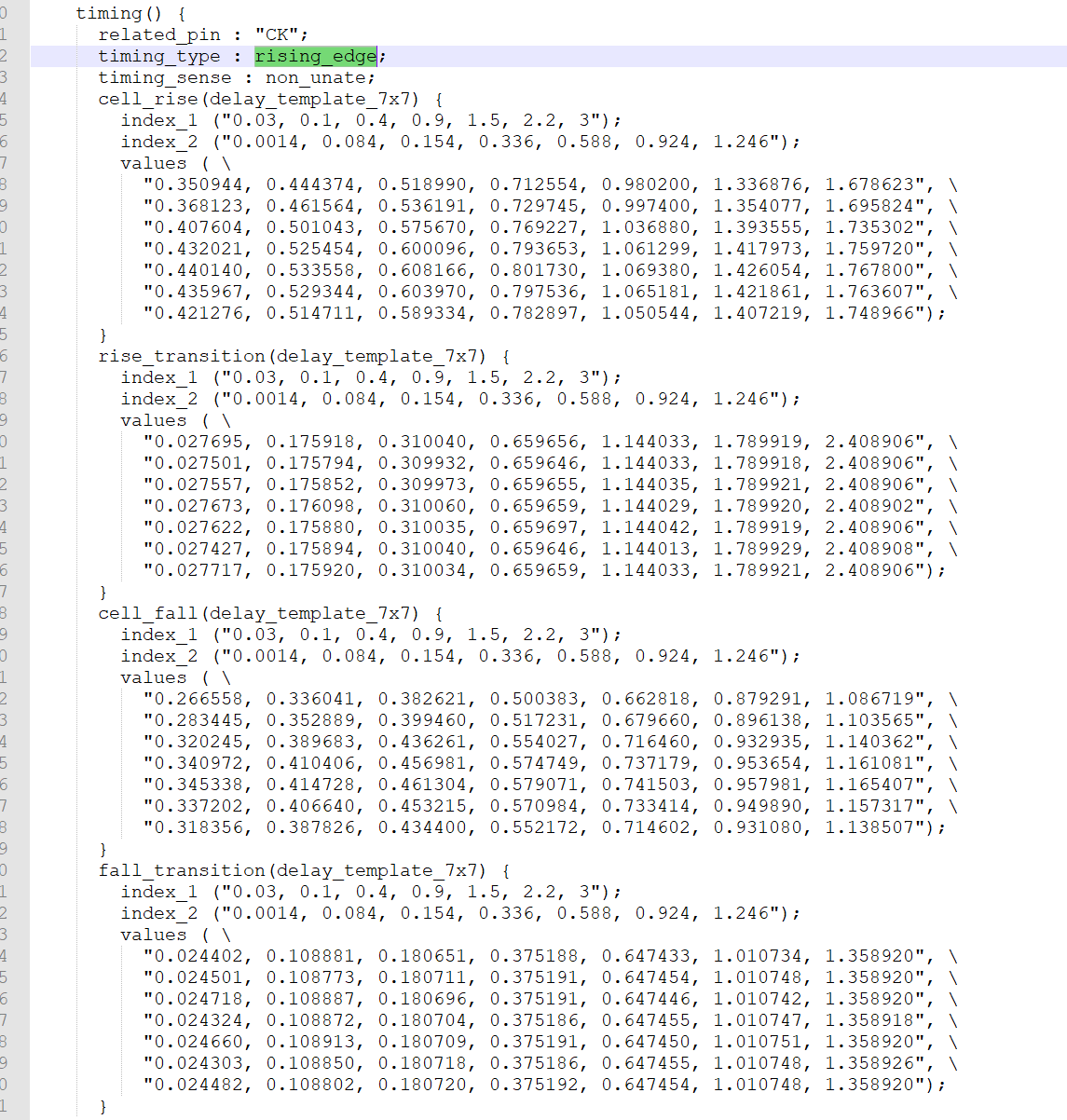
PIN(Q)与CK有关的传播延时。
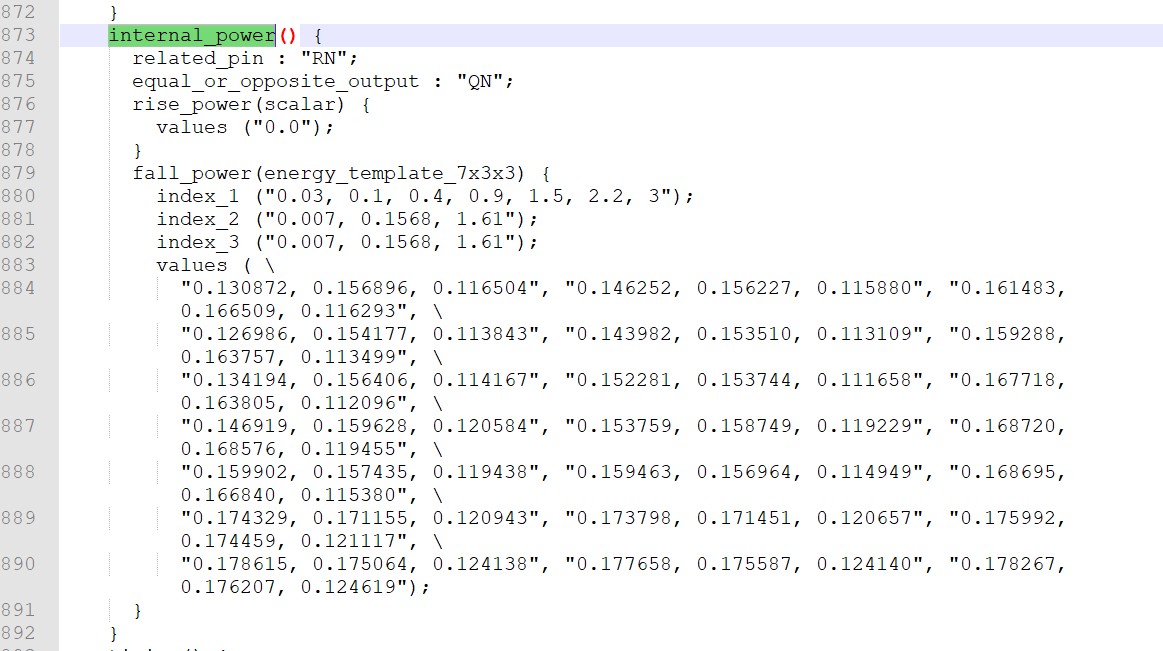
对于Q还在引脚级别定义了功耗。
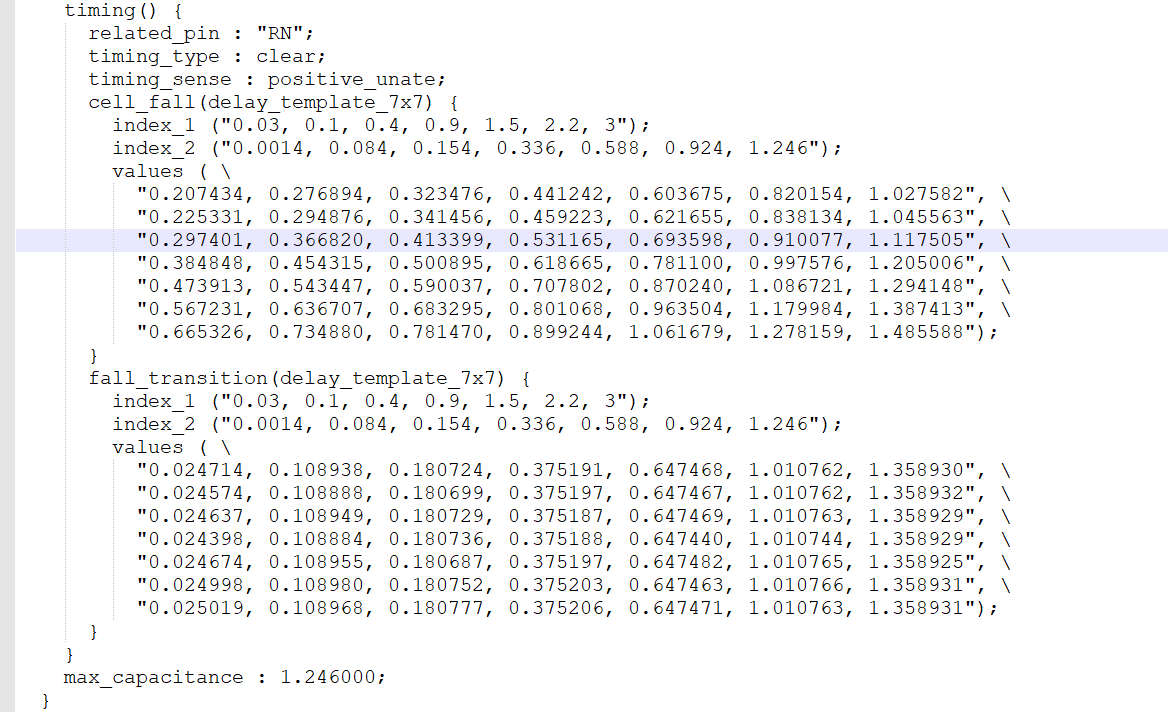
这里的时序弧类型是负单边(negative unate)类型
如果输入引脚上的上升沿跳变导致输出引脚电平下降(或不变),而输入引脚上的下降沿跳变导致输出引脚电平上升(或不变),则时序弧为负单边(negative unate)类型 。当复位有效时候,输输出变为0的延时时间。注意这里只有下降,很好理解,当你复位的时候,要是Q是0的话,也就不需要进行动作了。同时定义了max_capacitance。
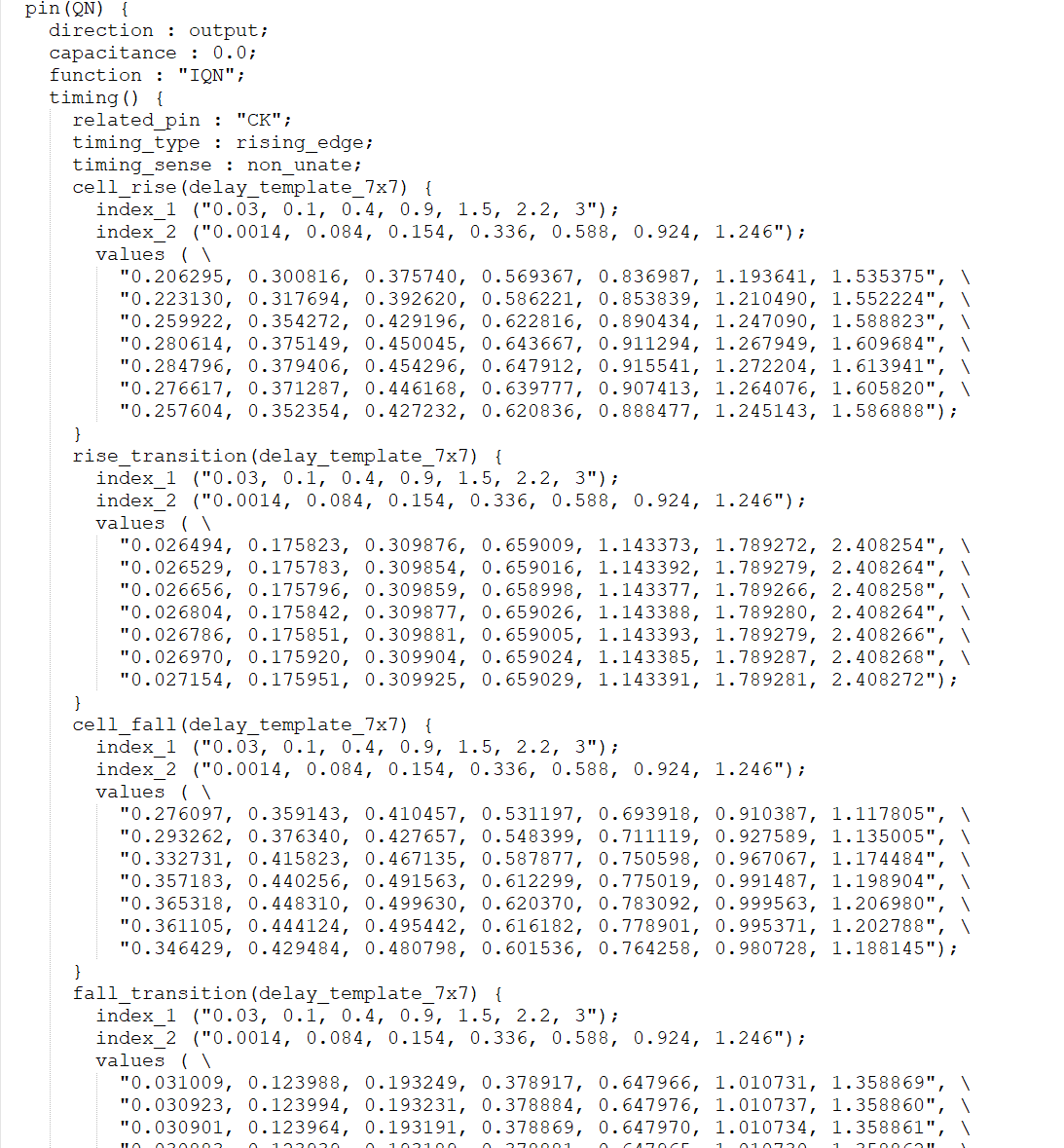
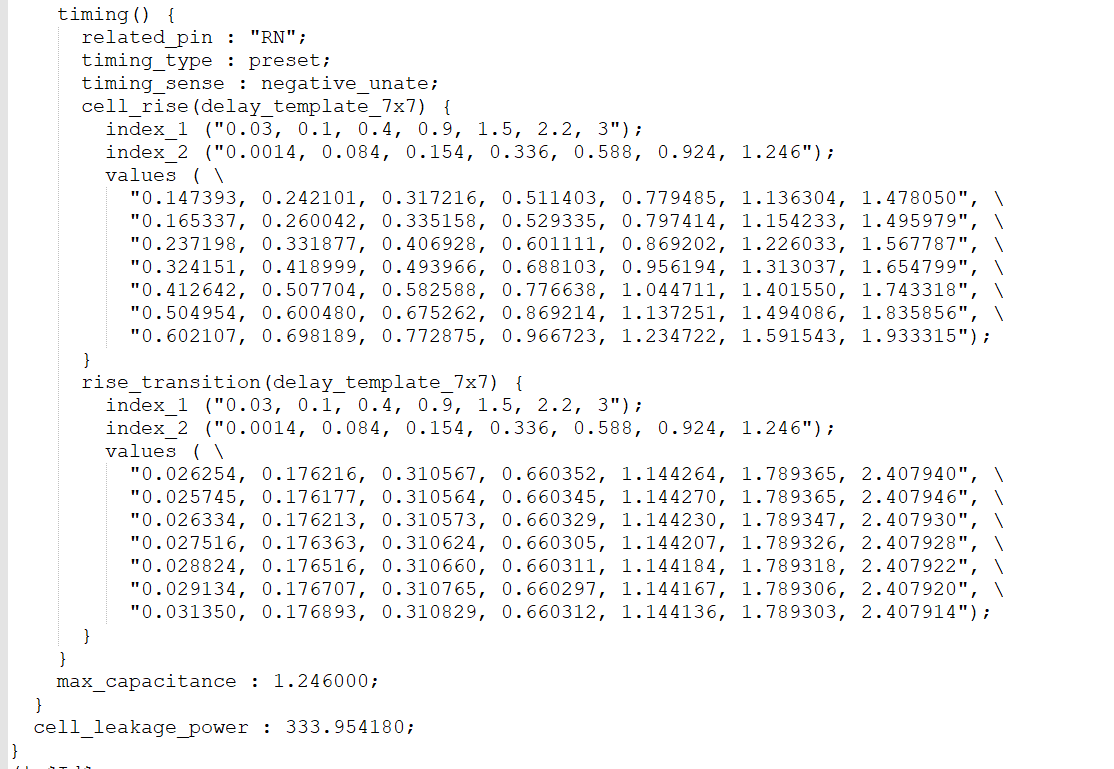
对于引脚QN的时序模型。与Q的模型很类似,这里不进行分析。
总结一下对于DFFR的时序模型。CK对于D查建立时间,保持时间。对复位查恢复撤离时间,对于Q计算传播延时,对于CK本身,查脉冲宽度。

至此,前面总结了STA的相关知识,这里对于DC综合标准单元lib库进行了学习,后续将开始时钟的学习。
 微信
微信 支付宝
支付宝





