hexo博文写作——Typora的使用
hexo博文写作——Typora的使用
Typora是一款Markdown编辑器,可以使得你的编辑所见即所得。Typora更多的快捷键以及可以和图床PicGo进行联合使用(图床就是专门用来存放图片,允许你把图片对外连接的网上空间)。从而方便的进行文本编辑而不需要去关心图片的管理问题。其次使用简单,方便,保存都是在本地进行管理,可以保证数据的安全,页面简介简单,功能非常强大。
简单来说有以下的优点:
- 快捷键多,文本编辑速度快
- 图片管理极为方便
- 功能强大,页面简介
接下来介绍安装,常用快捷键的使用,图床的设置与相关问题安装地址
Typora支持地址
官网下载地址
常用快捷键
标题
在Typora中,也可以使用快捷键Ctrl+1(2,3,4,5,6)表示相对应的标题。Ctrl+0表示段落。
字体
一般使用的字体如下
| 字体描述 | 快捷键 |
|---|---|
| 黑体 | Ctrl+B |
| 下划线 | Ctrl+U |
Alt+Shift+5 |
|
| 斜体 | Ctrl+Shift+I |
选中字体使用快捷键即可,也可以直接使用后输入文本。
文本颜色与大小
可以使用使用<font> </font>标签来改变字体的颜色及大小。
如下:所示<font size=3 color="red">字体颜色为红色,大小为3</font><font size=4 color="blue">字体颜色为蓝色,大小为4</font><font size=6 color="violet">字体颜色为紫罗兰,大小为6</font>
字体颜色为红色,大小为3
字体颜色为蓝色,大小为4
字体颜色为紫罗兰,大小为6
文本高亮
使用==需要高亮的文字==
注意,这里的高亮需要打开文件->偏好设置进行设置。或使用快捷键Ctrl+,直接打开,设置如下图所示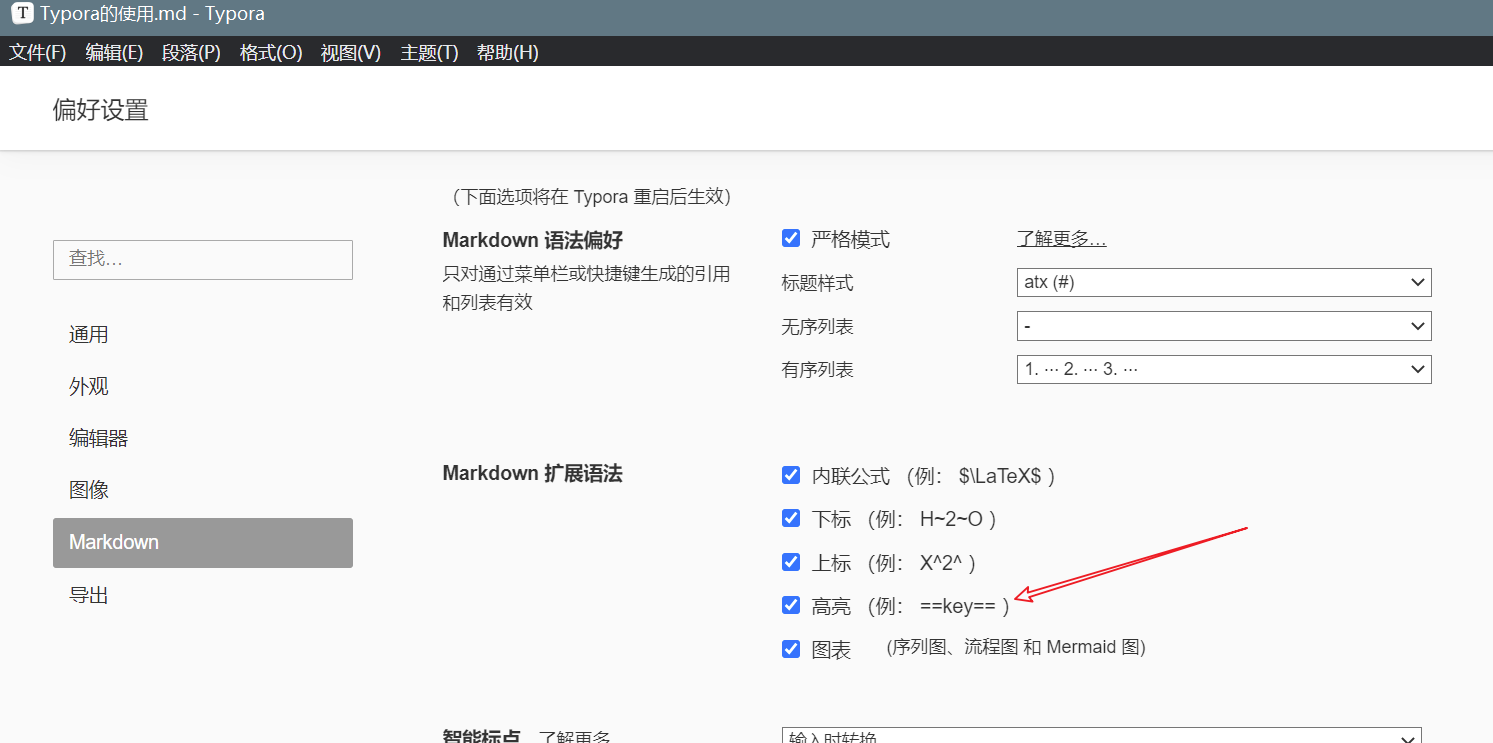
表格
使用Ctrl+T进行表格
| 说明 | 快捷键 |
|---|---|
| 创建表格 | Ctrl+T |
| 删除行 | Ctrl+Shift+Backspace |
| 添加行 | Ctrl+Enter |
列表
可以添加有序列表与无序列表
| 列表 | 快捷键 |
|---|---|
| 有序列表 | Ctrl + Shift + [ |
| 无序列表 | Ctrl + Shift + ] |
演示:
- 有序列表1
- 有序列表2
引用
使用快捷键
Ctrl+Shift+Q
超链接
复制网址后直接使用快捷键Ctrl+K
点击我的博客跳转
目录
直接使用[TOC]在文章的开头即可
换行问题
使用Typora的时候,直接使用Enter时候会有一个空格,需要使用shift+enter进行换行即可。举例如下:
直接使用Enter
这是第一行
这是第二行
使用shift+Enter进行换行
这是第一行
这是第二行
图床的设置于相关问题
安装与配置问题
–建议这里使用github+PicGo+CDN搭建自己的图床,简单好用,免费。具体设置如下–
1,下载PicGo
github地址:https://github.com/Molunerfinn/picgo/releases
选择latest版本即可,下载对应的版本,笔者使用的如下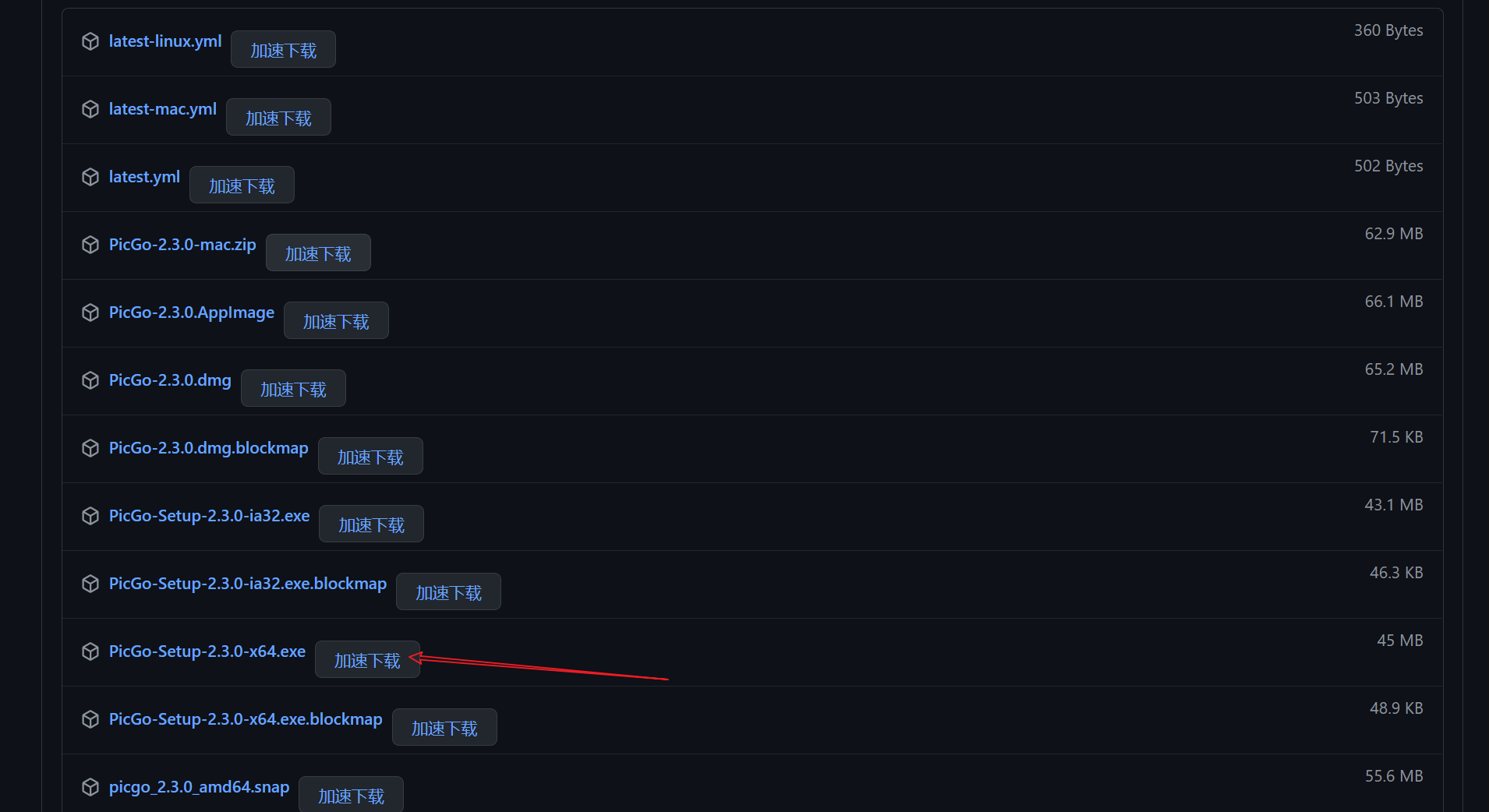
下载完成后安装即可。
2,软件配置
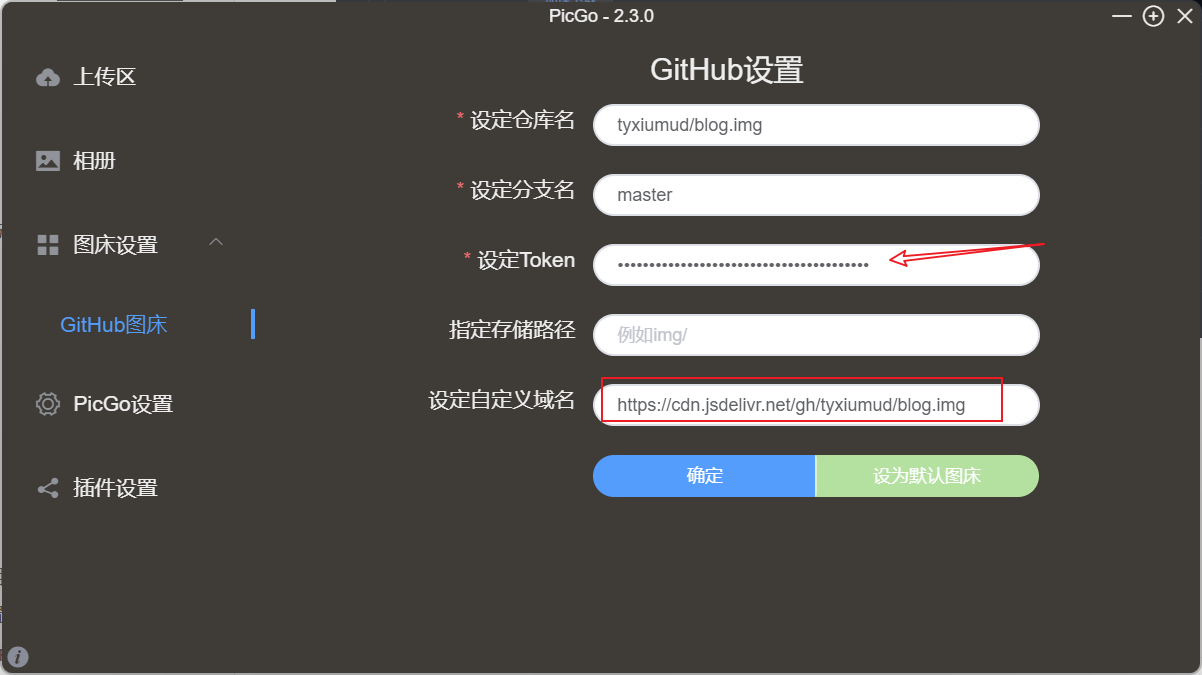
获取你github上的Token,填入即可,然后设定你的自定义域名如下https://cdn.jsdelivr.net/gh/+tyxiumud/blog.img
我的仓库名称。这里仓库的建立于Token获取方式自行百度。
3,在Typora中使用
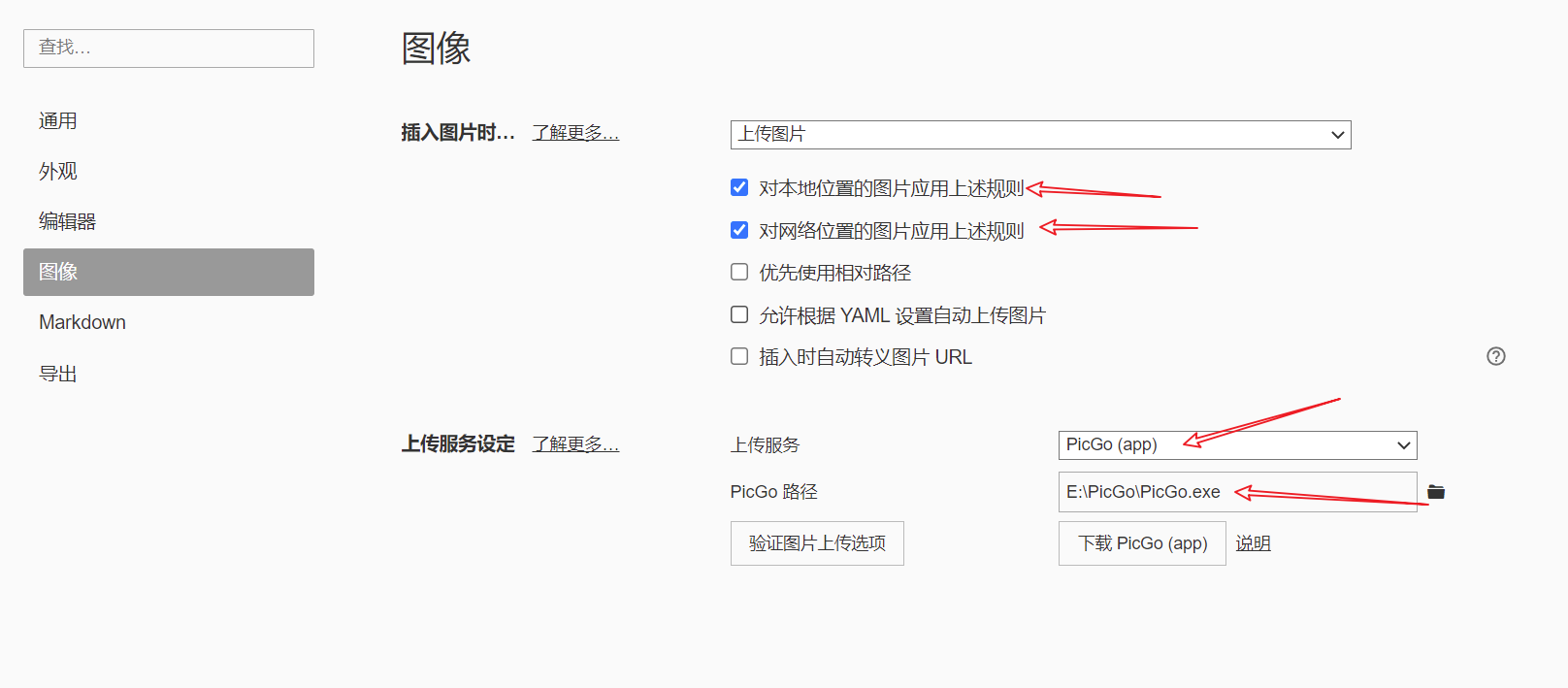
这里验证上传选项要是验证不通过也不用担心,编辑界面可以点击图片上传或者图片会自动上传到你的仓库。
4,将文章图片整理保存(建议)
数据无价,本地的或许是最安全的,每次写完一篇笔记文章建议进行对其中的图片进行保存C:\Users\username\AppData\Roaming\Typora\typora-user-images可以找到对应的图片。
要是有需要的话将其自行整理保存即可。
CSDN 转存失败问题解决
将Typora的文章转到CSDN时候会出现问题。使用如下脚本替换图片显示的方式即可。参考链接
import re |
最后输出的文件复制到csdn即可。
 微信
微信 支付宝
支付宝



